728x90
메모리가 모자라서 생기는 문제였다.
필요없는 메모리를 삭제하기로 결정했다.
sudo fuser -v /dev/nvidia*cuda를 쓰고 있는 메모리들 확인이 가능하다.
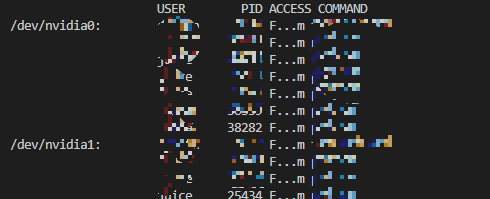
sudo kill -9 PID안쓰는 메모리들을 kill해주면 쓸 수 있는 메모리가 많아져 다시 코드를 돌릴 수 있다.
728x90
'Pytorch' 카테고리의 다른 글
| VS Code에서 pytorch 사용을 위한 python 환경 설정 (0) | 2022.12.16 |
|---|