멀티모달 비디오 캡셔닝 시스템
멀티모달 비디오 캡셔닝 시스템들은 비디오의 캡션을 생성하기 위해 비디오 프레임과 스피치를 이용합니다.이 시스템들은 노력없이 사용자들과 의사소통을 하며 멀티모달 인풋 스트림들을 통해 환경들을 인식하는 멀티모달 의사소통 시스템들을 만드는 데 일조할 수 있을 것으로 보입니다.
기존 멀티모달 비디오 캡셔닝 방법의 한계점
이 멀티모달 비디오 캡셔닝은 기존에 비디오 이해 태스크에서 있었던 멀티모달 인풋 비디오들을 처리하고 이해하는 것 말고도, grounded 캡션들을 만드는 것에도 추가적인 이슈가 존재합니다.
가장 많이 사용하는 방법은 메뉴얼하게 annotate된 데이터를 이용하여 encoder-decoder 네트워크를 묶어서 학습하는 것입니다. 하지만 메뉴얼하게 annotate된 데이터가 현실적인 이유로 많이 없기 때문에 기존의 VideoBERT and CoMVT은 그들의 모델을 automatic speech recognition(ASR)을 이용하여 레이블되지 않은 비디오들을 pre-train하는 방식을 택했습니다.
하지만, 이런 모델들은 주로 비디오 인코더를 학습하여 다운스트림 태스크에 전이하는 것을 주 목적으로 하고 있기 때문에, 자연어를 만들어 내는 decoder가 부재했습니다.
새로운 멀티모달 비디오 캡셔닝, MV-GPT 제안
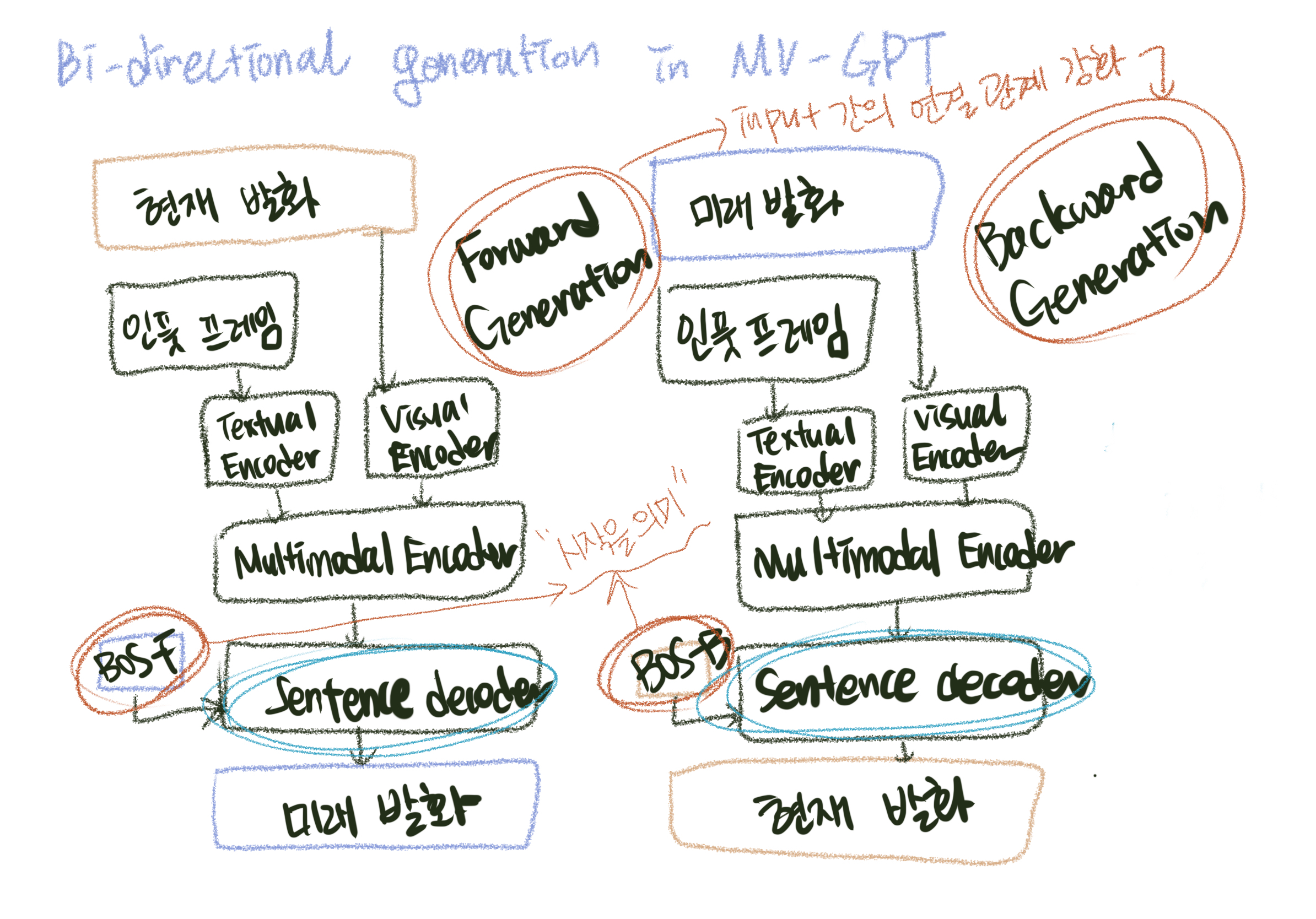
이 연구에서는 멀티모달 비디오 캡셔닝을 하기 위한 새로운 pre-training 프레임워크를 만들었고, 이를 MV-GPT(multimodal video generative pre-training)라 했습니다. 이는 멀티모달 비디오 인코더와 문장 디코더를 묶어서 학습하는 방법을 사용하였는데, 이 때 레이블 되지 않은 비디오들을 기반으로 미래 발화를 타겟 텍스트로 이용하였습니다. 그리고 새로운 양방향 생성 태스크를 만들었습니다.
멀티모달 비디오 캡셔닝에서 보통 각 학습 비디오 클립은 두 가지의 텍스트와 연관이 있습니다. 첫번째는 스피치 스크립트(transcript)으로 클립과 맞춰져서 멀티모달 인풋 스트림의 일부로 들어오는 부분이고, 두번째는 타겟 캡션으로 주로 메뉴얼하게 annotation되는 부분입니다.
인코더는 비쥬얼 컨텐츠를 스크립트과 함께 학습하여 정보를 얻어내고 타겟 캡션은 디코터에서 생성을 하는데 학습하기 위해 이용됩니다. 그러나 레이블되지 않은 비디오들에서는 각 비디오 클립은 ASR에서 나오는 스크립트만 갖고 있고 따로 메뉴얼하게 annotate한 타겟 캡션은 존재하지 않습니다. 그렇다고, 인코더와 디코더에 같은 텍스트(ASR로 만든 스크립트)를 쓰면 생성되는 타겟이 너무 쓸데없어지기 때문에 이런 방식을 쓸 수도 없습니다.
MV-GPT에서는 이를 해결하기 위해서 미래 발화를 추가적인 텍스트 시그널로 이용하고 인코더와 디코더가 같이 pre-training을 할 수 있도록 만들었습니다. 그러나 미래 발화를 생성하기 위해 인풋 컨텐츠에 기반하지 않고 모델을 학습하는 것은 좋지 않습니다. 그래서 이들은 새로운 양방향 생성 loss를 만들어서 인풋 간의 연결 관계를 강화시켰습니다.
기반이 없는 텍스트 생성에서의 이슈는 forward와 backward 생성을 포함하는 양방향 생성 loss를 만들어 완화시킬 수 있습니다. Forward 생성은 주어진 시각적인 프레임들과 해당하는 스크립트들을 기반으로 미래의 발화를 만들게 되고, 이를 통해 모델이 시각적인 컨텐츠와 그에 대응하는 스크립트을 같이 학습될 수 있게 합니다. Backward 생성은 비디오 클립의 더 기반적인 텍스트인 스크립트 생성을 위한 모델을 학습하기 위해 시각적인 프레임과 미래 발화들을 사용합니다. 이를 통해 MV-GPT에 있는 양방향 생성 loss는 인코더와 디코더가 시각적인 기반 텍스트들 처리하여 학습할 수 있게 합니다.
멀티모달 비디오 캡셔닝과 비디오 이해 태스크에서의 성능
여기서는 기존의 pre-training loss들과 MV-GPT를 비교하였습니다. 이 때 YouCook2 데이터셋을 사용하면서 네 가지 메트릭들을 사용하였습니다.
디코더를 함께 pre-train 하는 것이 중요하다는 것을 알 수 있었습니다. MV-GPT는 기존의 pre-training 기반의 기법들과 비교하여 더 나은 결과를 도출함을 알 수 있었습니다. "pre-trained parts"는 어떤 파트를 사전 학습했는 지를 가르킨다.

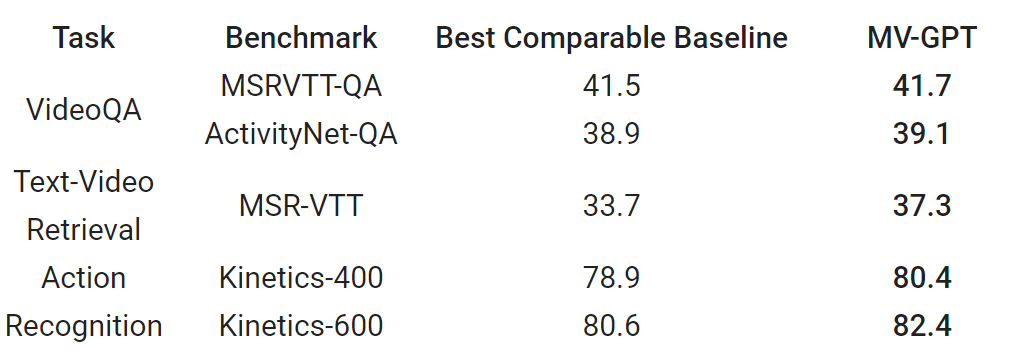
우리는 네가지 캡셔닝 벤치마크에 MV-GPT로 사전 학습한 모델을 테스트해보았을 때 이전 SOTA에 비해서 퍼포먼스가 잘 나온다는 걸 확인할 수 있었습니다. 결국, MV-GPT는 기존 SOTA에 비해 다양한 벤치마크에서 보다 나은 성과를 내었다는 결론이 납니다.

뿐만 아니라 멀티모달 비디오 인코더는다수의 비디오 이해 태스크(VideoQA, text-video retrieval, and action recognition)에서 경쟁력이 있음을 확인할 수 있었습니다. MSRVTT-QA와 ActivityNet-QA에서는 Top-1 정답 정확도, MSR-VTT은 Recall at 1 그리고 Kinetics: Top-1 분류 정확도를 기반으로 성능 측정을 하였습니다.
본 내용은 "End-to-end Generative Pre-training for Multimodal Video Captioning"을 참고하여 작성하였습니다.
(https://ai.googleblog.com/2022/06/end-to-end-generative-pre-training-for.html)