딥러닝의 데이터에 대한 역설적인 사실
오늘 공부할 것은 ICML 2020에 출판된 제어된 노이즈 레이블에서의 딥러닝 이해(Understanding Deep Learning on Controlled Noisy Labels)에 대한 내용입니다. 트레이닝 데이터에서 레이블 에러(레이블 노이즈)가 있는 것은 모델 테스트 시에 정확도를 급격하게 낮출 수 있습니다. 그러나 방대한 데이터에는 이러한 레이블 이슈가 생길 수밖에 없습니다. 딥러닝을 위해서는 방대한 양의 데이터가 필요한 것과 실제 환경에서는 방대한 데이터 안의 오류를 딥러닝 모델이 기억한다는 것은 역설적인 관계를 가진다고 할 수 있습니다.
인공적인 데이터 기반 모델의 한계
이를 해결하기 위해 다양한 연구들이 제안되었습니다. 통제된 실험은 노이즈 레벨 정도(노이즈 레이블이 데이터셋에 얼마나 있느냐)가 모델의 성능에 미치는 효과를 연구하여 노이즈 레이블을 이해하는 데 사용되었습니다. 그러나 현재의 실험들은 인공적으로 만들어진 레이블 위에서 실험을 하기 때문에 실제 환경에서 생기는 노이즈와 다를 수 있습니다. 이는 실제적인 상황과 매우 다르거나 모순적인 발견을 하게 유도할 수도 있고 인공적인 데이터 기반으로 만들어진 모델은 현실적인 노이즈 레이블에 제대로 작동이 안 될 가능성이 높습니다.
세 가지 방법을 이용한 해결방법
이를 해결하기 위해, 1. 웹에서 가져온 사실적이고 현실적인 레이블 노이즈에 대한 최초의 제어된 데이터셋과 벤치마크를 위축하고, 2. 인공적인 노이즈 레이블과 실생활의 노이즈 레이블을 모두 커버할 수 있는 심플하고 매우 효과적인 방법을 제안하고, 3. 매우 다양한 세팅에서 인공적인 노이즈 레이블과 웹 노이즈 레이블(1번)에 비교하는 방대한 연구 수행하였습니다.
인공적으로 만든 데이터와 실제(웹) 레이블 노이즈 사이에는 다른 점들이 존재합니다.
1. 웹 레이블 노이즈가 있는 이미지는 실제 참인 이미지와 (시각적으로나 의미적으로)일관성을 가지는 부분들이 있습니다.
2. 같은 클래스에 속하는 경우 같은 노이즈를 가지는 인조적인 레이블 노이즈(클래스 중심)와 달리 실제 레이블 노이즈는 클래스에 상관없이 어떤 각 이미지들이 다른 것들에 비해 잘못 레이블되는 경우가 많습니다(인스턴스 중심). 즉, A라는 차가 있고, 비슷한 B라는 차가 있으면 인조적인 레이블 노이즈들은 A라는 차의 이미지들 중에서, B라는 차의 이미지들 중에서 노이즈된 레이블을 만듭니다. 이와 다르게 현실적인 레이블 노이즈는 A의 앞모양을 봤을 때는 A라고 잘 인식하지만 A의 옆모양을 봤을 때 B라고 인지하는 경우가 많아지는 등의 인스턴스 단의 노이즈가 발생합니다.
3. 실제 레이블 노이즈가 있는 이미지들은 특정 데이터셋에 클래스 어휘와 겹치지 않는 개방형 클래스 어휘에서 도출됩니다. 즉, "무당벌레"의 웹 노이즈 이미지 레이블에는 파리나 다른 곤충들을 포함할 수 있는데 이는 해당 데이터셋의 클래스 리스트에는 포함되어 있지 않는 경우가 많다는 것입니다.
웹(Web) 기반의 제어된 레이블 노이즈에 대한 벤치마크 제안(Controlled Noisy Web Labels website)했습니다. 조잡한(거친) 이미지 분류를 위한 Mini-ImageNet과 세밀한 이미지 분류를 위한 Stanford Cars 데이터셋 두 가지 데이터셋을 기반으로 웹에서 가져온 것을 기반으로 잘못된 레이블 이미지들을 기존의 클린한 이미지들과 섞습니다. 또한, standard methods을 이용하여 인공적인 데이터셋도 만들었습니다.
웹에서 클래스 이름을 이용하여 이미지들을 긁어온 다음 Google Cloud Labeling Service를 이용하여 긁어온 이미지들에 대한 레이블이 알맞은 지 확인합니다. 그리고 잘못된 레이블을 가진 웹 이미지들을 두 개의 기존 데이터셋에 섞습니다. 노이즈 데이터의 정도에 따라 10개의 다른 데이터셋이 만들어집니다.

이런 노이즈에 불구하고 학습이 잘 되는 심플하고 강력한 모델 MentorMix을 만들었습니다. 이는 두 가지 기존의 기술들(MentorNet과 Mixup)을 이용한 반복적인 접근법입니다.
1. Weight 스탭 : MentorNet에 의해 mini-batch에 있는 모든 예시들에 대한 당면한 태스크에 맞게 가중치가 계산되고 가중치들은 분포에 의해 정규화됩니다. 즉, 제대로된 예시들에 대해서는 높은 가중치를 주고, 잘못 레이블된 예시들에 대해서는 낮은 가중치를 부여하는 것을 목표로 합니다. 그러나 현실적으로 우리는 어떤 것이 옳고 그름을 알기 어려움으로 MentorNet의 가중치들은 근사치를 기반으로 합니다. 여기서는 분포에서의 가중치를 결정하기 위해 StudentNet 학습 loss를 이용합니다.

2. Sample 스탭 : 분포에 따라 동일한 mini-batch에서 다른 예시를 선택하기 위해 importance sampling 사용합니다. 높은 가중치들을 가지고 있는 예시들은 알맞은 레이블을 가지고 있는 경향을 가지고 있어 샘플링 절차에서 선호됩니다.

3. Mixup 스탭 : 기존과 2번에서 샘플링된 예시들을 섞어서 모델이 둘 사이를 보간하고 노이즈 학습 예시들에 오버피팅되는 것을 막습니다.
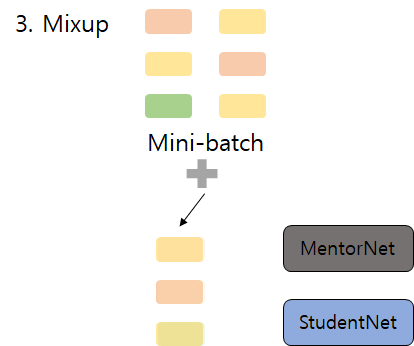
4. 1번 과정 다시 : 3번의 섞여진 예시들의 가중치들을 다시 계산하여 최종 손실을 조정합니다. 두 번째 가중치 전략은 높은 노이즈 레벨에서 더 큰 효과를 가집니다.

노이즈 학습 예시들 기반 검증 및 인사이트
결과적으로 웹 기반의 노이즈 학습 예시들을 가지고 정돈된 테스트 데이터로 검증시에 3%이상의 향상 효과를 가지게 됩니다. 웹 레이블 노이즈에 대한 인사이트는 다음과 같습니다.
1. 딥러닝이 웹 레이블 노이즈에 상당히 효과적입니다. 같은 노이즈 레벨일 때, 인공적인 데이터를 기반으로 학습시에는 0.09밖에 안되지만 현실적인 웹 레이블 노이즈에는 0.66까지의 정확도를 도출합니다.
2. 딥러닝 네트워크가 웹 레이블 노이즈에서 학습시에는 패턴을 먼저 학습 못할 수도 있습니다. 기존의 생각들은 신경망이 패턴을 먼저 학습하기 때문에, 잡음이 있는 학습 레이블들을 기억하기 전에 초기 학습 단계에서 일반화 가능한 패턴들을 자동으로 캡처할 수 있다는 것입니다. 그래서 노이즈 데이터들을 학습시에는 early stopping 방법이 제안됩니다. 하지만, 본 연구의 결과에 의하면 (적어도 세밀한 분류 태스크에 대해) 웹 레이블 노이즈가 있는 데이터셋을 이용해 학습시에는 먼저 패턴을 알아내지 못할 수도 있다는 것이 보입니다. 이는 early stopping 방법이 과연 효과적인가에 대해 의문을 가져야 합니다.
3. 네트워크가 fine-tuned되면, ImageNet구조들은 노이즈 학습 레이블들에도 일반화됩니다. 이전 논문은 ImageNet에서 학습된 발전된 구조들을 fine-tuning하면 타겟팅하는 태스크에서 더 잘 수행되는 것을 발견했습니다. 이것을 기반으로 ImageNet에서 사전 훈련되었을 때 더 좋은 성능을 보여주는 사전 훈련된 구조가 노이즈 학습 레이블에서 fine-tuned 되는 경우에도 좋은 성능을 나옴을 보여줍니다.
결론적으로, ImageNet같은 클린한 데이터셋을 기반으로 사전 학습을 하고 노이즈 레이블에 대해 fine-tuning하면 쉽고 좋은 성능을 가지는 모델이 나왔습니다. Early stopping이 실제 레이블 노이즈에는 그리 효과적이지 않을 수 있습니다. 인공적인 노이즈에서 잘 작동했다고 웹에서 가져온 현실적인 노이즈에 잘 작동한다고 할 수 없습니다. 웹에서 가져온 레이블 노이즈는 그다지 심각해 보이지는 않지만, 아직 제안된 학습 방법으로는 해결하기 어려운 부분이 있어 더 많은 연구가 요구된다고 생각합니다. 제안된 MentorMix는 인공적인 데이터와 현실적인 노이즈 데이터에 모두 잘 작동했습니다.