발화 표현과 개인화 모델 개선이 필요함
오늘은 Self-supervision을 이용한 발화 표현과 개인화 모델 개선(Improving Speech Representations and Personalized Models Using Self-Supervision)에 대한 내용입니다. 그동안 연구되어온 오디오에서 텍스트 변환 등의 발화 관련 태스크는 많은 데이터양을 기반으로 합니다. 이러한 "언어적" 태스크뿐만 아니라 화자 인식, 감정 인지 등의 사람의 발화 자체를 포커스 하는 비의 미적인(Non-Semantic) 다양한 태스크에도 발화 분석 기술들이 쓰일 수 있습니다. 비언어적인 태스크에도 많은 데이터가 있으면 딥러닝 기반의 기존 접근법들이 좋은 결과를 내겠지만 데이터 셋이 적은 경우에는 성능이 잘 안 나올 수 있습니다. 따라서, 큰 데이터 셋에서 표현 모델(representation model)을 학습한 후 적은 데이터 셋으로 표현을 전이하는 방법들이 쓰입니다.
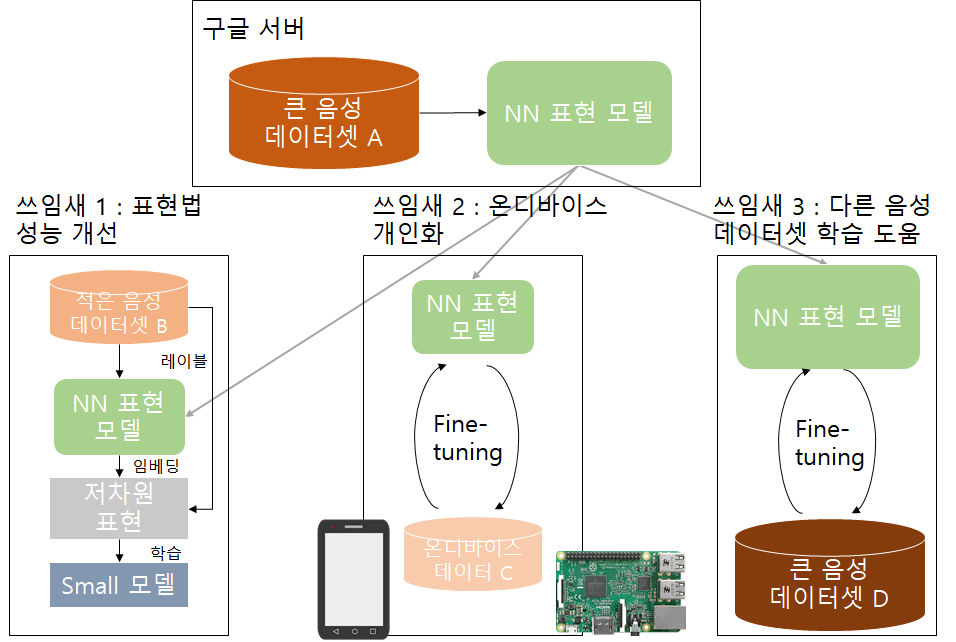
표현법(Representations)의 성능 발전될 수 있는 방안이 있는데, 고차원의 데이터를 저차원으로 변환하여 작은 모델들로 학습시키고 미리 학습된 표현 모델을 Pre-training으로서 사용하는 것입니다. 학습된 표현 모델이 충분히 작다면 디바이스 안(on-device)에서도 학습과 추론이 되므로 사용자 프라이버시를 지키는 데 일조할 수도 있습니다.
이런 표현법 학습은 다른 분야(텍스트- BERT , ALBERT , 이미지- Inception layers , SimCLR))에서는 많이 쓰이고 있지만, 발화 분야에서는 아직 더디게 쓰입니다. 또한, 텍스트 쪽 분야나 이미지 분야와 달리 표준적인 비의미적 발화 임베딩에 대해 기준(Benchmark)이 없어서 연구에 어려움이 생깁니다.
Self-supervision을 이용한 개선 방안
문제를 해결하기 위해 다음과 같은 세 가지를 고려하여 방법 제안합니다.
① 다양한 데이터 셋과 태스크를 포함하여, 비의미적 발화(NOSS: NOn-Semantic Speech) 분야의 기준을 제시합니다.
② 다른 표현 학습법의 성능을 능가하면서 온 디바이스에서도 적용 가능한 작은 모델을 만들어서 오픈소스화합니다( TRIpLet Loss network (TRILL)).
③ 다른 표현 학습법들과 비교하는 대규모의 연구를 하고 새로운 표현 학습법에 대해 오픈소스화합니다.
기준(Benchmark)을 제시되기 위해서는 선택된 태스크들이 비슷한 해결 방법으로 풀릴 수 있어야 합니다. 따라서 이 포스팅에서는 발화 태스크의 하위 개념인 비의미적 발화(NOSS)을 중심으로 기준 제시합니다. 태스크 기준이 되기 위해서는 다음 조건을 만족해야 합니다. 1) 다양한 사용 사례들이 포괄되어야 하고, 2) 문제일만큼 복잡해야 하고, 3) 오픈 소스화시킬 수 있게 가용성이 있어야 합니다. 이에 따라 여섯 가지 태스크(Speaker idenfication, Language identification, Emotion, etc.)를 가진 데이터 셋이 NOSS의 기준으로 제시됩니다. 그리고 개인화 시나리오를 위해 3가지 태스크도 추가합니다. 이 태스크를 통해 특정 발화자에게 잘 적응하고 개인화되는지, 온 디바이스에서 모델이 잘 작동하는지 등을 실험해 볼 수 있습니다.
새로운 NOSS 분류 기법도 제시하였습니다(위에서 말한 TRILL). 기존의 발화에 대한 표현 방법들은 적고 덜 다양한 데이터로 학습이 되거나 발화 인식 태스크만을 위해서 모델이 만들어지는 경우가 대다수였습니다. 다양한 환경과 태스크에 대해 활용도 있는 표현 방법을 만들기 위해서 AudioSet이라는 크고 다양한 데이터셋을 이용했습니다.

같은 오디오에 들어있는 임베딩들끼리는 임베딩 공간에서 가깝게 다른 오디오에 있는 것끼리는 멀리하는 간단하고 Self-supervised 방법을 통해서 임베딩 모델을 학습합니다. Self-supervised Loss함수는 레이블이 필요 없이 데이터 자체만으로 학습이 됩니다. NOSS가 시간에 따라 특성이 달라질 수 있기 때문에 이 방법이 잘 맞고 다양한 음성적 특성을 찾아낼 수 있습니다.
TRILL은 MobileNet을 기반 구조로 모바일 기기들에서 충분히 활용 가능합니다. 임베딩 부분은 더 큰 RestNet50 모델(Pre-traning)을 기반으로 결과를 가져와서 사용되기 때문입니다.
TRILL의 성능 비교 결과와 논의점
TRILL을 도메인이 다르고 여러 데이터 셋으로 학습된 다른 딥러닝 기반 표현법들과 비교해 보았습니다. 또한, 발화 분야에서 음성의 특성을 분석하는 데 중요한 기준이 되는 딥러닝 기반이 아닌 OpenSMILE과도 성능 비교해 보았습니다. 모든 기법들은 다양한 태스크에 대해서 학습하고 각 태스크들에서 나온 정확도들을 모델들과 엮어서 Linear regression을 이용하여 분석해 본 결과 TRILL이 대체적으로 다른 표현법들에 비해 성능이 좋은 것을 알 수 있었습니다. 이는 다양한 학습 데이터 셋으로의 학습이나 음성의 특성에 대한 보편적인 특성 파악 등을 TRILL이 잘해서 나타나는 결과였습니다. 학습 데이터가 적은 새로운 데이터 셋에 대해서도 좋은 성능이 나오고 마스크 등을 쓴 상태에서의 발화에서도 좋은 성능이 나왔습니다. 결론적으로, 이 포스팅의 방법은 비의미적 발화와 관련하여 다양한 태스크에서 쓸 수 있고 개인화나 적은 데이터 셋 문제에 대한 어떤 초기 기준을 마련해 줌을 의미합니다.
언어적인 연구를 볼 때마다 느끼는 이슈인데, 영어 기반일 때는 가능하지만 Pre-traning을 할 정도의 데이터 자체가 없는 다른 나라들의 발화도 같은 성능이 나올 수 있을까라는 생각이 듭니다. 또한, 문화적 특성이나 양식 때문에 NOSS는 더 많은 노이즈가 생길 수 있지 않을까? 이런 부분들은 사회문화적 연구와 같이 결합하여 연구를 해야 하지 않을까? 등등 많은 이슈들이 떠오릅니다. Syntax 적인 요소보다 Sematic 한 요소를 파악하는 것이 어렵다고 생각했는데, 이 포스팅의 경우에는 그것을 넘어서 Non-Semantic 한 상황적인 부분까지 파악하는 연구이니 당연히 더 어렵고 앞으로 나아가야 할 길이 많을 것 같아 흥미로웠습니다. 작은 모델이라는 것과 모바일에서 쓸 수 있다는 점이 강조되어 있으니, 이에 대한 설명이 더 있었으면 좋았을 것 같고 결과 분석 시 이해 못 한 부분들이 좀 있는데 다시 봐야 할 것으로 보입니다.