멀티모달 비디오 캡셔닝 시스템들은 비디오의 캡션을 생성하기 위해 비디오 프레임과 스피치를 이용합니다.이 시스템들은 노력없이 사용자들과 의사소통을 하며 멀티모달 인풋 스트림들을 통해 환경들을 인식하는 멀티모달 의사소통 시스템들을 만드는 데 일조할 수 있을 것으로 보입니다.
기존 멀티모달 비디오 캡셔닝 방법의 한계점
이 멀티모달 비디오 캡셔닝은 기존에 비디오 이해 태스크에서 있었던 멀티모달 인풋 비디오들을 처리하고 이해하는 것 말고도, grounded 캡션들을 만드는 것에도 추가적인 이슈가 존재합니다.
가장 많이 사용하는 방법은 메뉴얼하게 annotate된 데이터를 이용하여 encoder-decoder 네트워크를 묶어서 학습하는 것입니다. 하지만 메뉴얼하게 annotate된 데이터가 현실적인 이유로 많이 없기 때문에 기존의 VideoBERT and CoMVT은 그들의 모델을 automatic speech recognition(ASR)을 이용하여 레이블되지 않은 비디오들을 pre-train하는 방식을 택했습니다.
하지만, 이런 모델들은 주로 비디오 인코더를 학습하여 다운스트림 태스크에 전이하는 것을 주 목적으로 하고 있기 때문에, 자연어를 만들어 내는 decoder가 부재했습니다.
새로운 멀티모달 비디오 캡셔닝, MV-GPT 제안
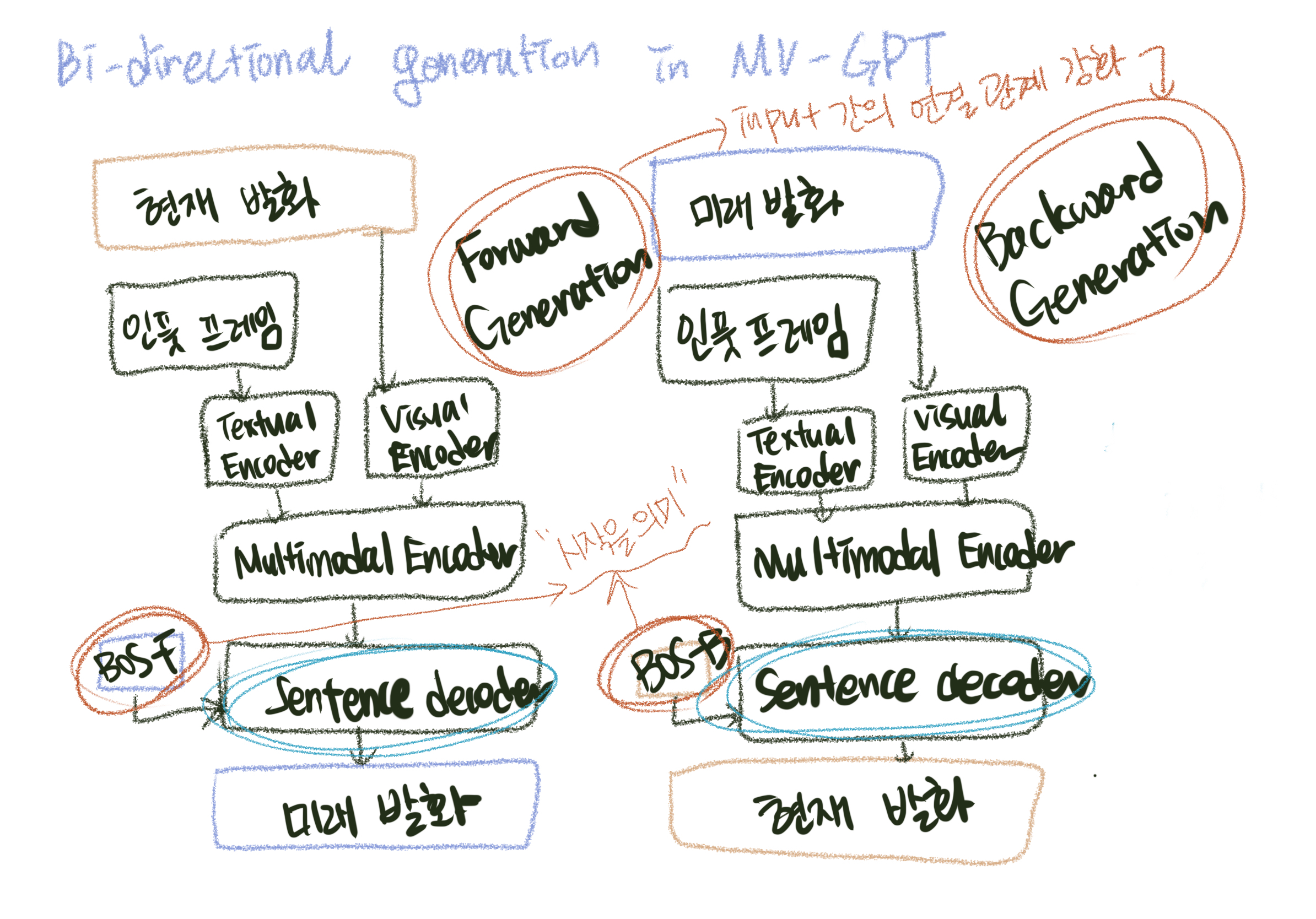
이 연구에서는 멀티모달 비디오 캡셔닝을 하기 위한 새로운 pre-training 프레임워크를 만들었고, 이를 MV-GPT(multimodal video generative pre-training)라 했습니다. 이는 멀티모달 비디오 인코더와 문장 디코더를 묶어서 학습하는 방법을 사용하였는데, 이 때 레이블 되지 않은 비디오들을 기반으로 미래 발화를 타겟 텍스트로 이용하였습니다. 그리고 새로운 양방향 생성 태스크를 만들었습니다.
멀티모달 비디오 캡셔닝에서 보통 각 학습 비디오 클립은 두 가지의 텍스트와 연관이 있습니다. 첫번째는 스피치 스크립트(transcript)으로 클립과 맞춰져서 멀티모달 인풋 스트림의 일부로 들어오는 부분이고, 두번째는 타겟 캡션으로 주로 메뉴얼하게 annotation되는 부분입니다.
인코더는 비쥬얼 컨텐츠를 스크립트과 함께 학습하여 정보를 얻어내고 타겟 캡션은 디코터에서 생성을 하는데 학습하기 위해 이용됩니다. 그러나 레이블되지 않은 비디오들에서는 각 비디오 클립은 ASR에서 나오는 스크립트만 갖고 있고 따로 메뉴얼하게 annotate한 타겟 캡션은 존재하지 않습니다. 그렇다고, 인코더와 디코더에 같은 텍스트(ASR로 만든 스크립트)를 쓰면 생성되는 타겟이 너무 쓸데없어지기 때문에 이런 방식을 쓸 수도 없습니다.
MV-GPT에서는 이를 해결하기 위해서 미래 발화를 추가적인 텍스트 시그널로 이용하고 인코더와 디코더가 같이 pre-training을 할 수 있도록 만들었습니다. 그러나 미래 발화를 생성하기 위해 인풋 컨텐츠에 기반하지 않고 모델을 학습하는 것은 좋지 않습니다. 그래서 이들은 새로운 양방향 생성 loss를 만들어서 인풋 간의 연결 관계를 강화시켰습니다.
기반이 없는 텍스트 생성에서의 이슈는 forward와 backward 생성을 포함하는 양방향 생성 loss를 만들어 완화시킬 수 있습니다. Forward 생성은 주어진 시각적인 프레임들과 해당하는 스크립트들을 기반으로 미래의 발화를 만들게 되고, 이를 통해 모델이 시각적인 컨텐츠와 그에 대응하는 스크립트을 같이 학습될 수 있게 합니다. Backward 생성은 비디오 클립의 더 기반적인 텍스트인 스크립트 생성을 위한 모델을 학습하기 위해 시각적인 프레임과 미래 발화들을 사용합니다. 이를 통해 MV-GPT에 있는 양방향 생성 loss는 인코더와 디코더가 시각적인 기반 텍스트들 처리하여 학습할 수 있게 합니다.
멀티모달 비디오 캡셔닝과 비디오 이해 태스크에서의 성능
여기서는 기존의 pre-training loss들과 MV-GPT를 비교하였습니다. 이 때 YouCook2 데이터셋을 사용하면서 네 가지 메트릭들을 사용하였습니다.
디코더를 함께 pre-train 하는 것이 중요하다는 것을 알 수 있었습니다. MV-GPT는 기존의 pre-training 기반의 기법들과 비교하여 더 나은 결과를 도출함을 알 수 있었습니다. "pre-trained parts"는 어떤 파트를 사전 학습했는 지를 가르킨다.
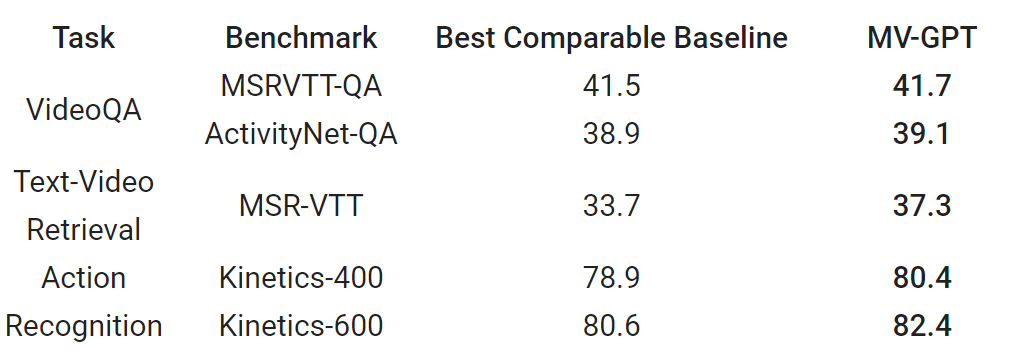
우리는 네가지 캡셔닝 벤치마크에 MV-GPT로 사전 학습한 모델을 테스트해보았을 때 이전 SOTA에 비해서 퍼포먼스가 잘 나온다는 걸 확인할 수 있었습니다. 결국, MV-GPT는 기존 SOTA에 비해 다양한 벤치마크에서 보다 나은 성과를 내었다는 결론이 납니다.
뿐만 아니라 멀티모달 비디오 인코더는다수의 비디오 이해 태스크(VideoQA, text-video retrieval, and action recognition)에서 경쟁력이 있음을 확인할 수 있었습니다. MSRVTT-QA와 ActivityNet-QA에서는 Top-1 정답 정확도, MSR-VTT은 Recall at 1 그리고 Kinetics: Top-1 분류 정확도를 기반으로 성능 측정을 하였습니다.
본 내용은 "End-to-end Generative Pre-training for Multimodal Video Captioning"을 참고하여 작성하였습니다.
기존 기법들은 모든 모델 프로세싱 부분들에서 모든 인풋들을 쓰고 있습니다. 하지만, 조건부적으로 계산법을 적용하는 sparse 모델들은잠재적으로 큰 네트워크에서 개별의 인풋들이 다른 "experts"들로 이동하도록 학습할 수 있습니다. 이에 따라 Sparse 모델들은 딥러닝 분야에서 점점 유망한 방법론이 되고 있습니다. 장점으로는, 계산 코스트를 일정하게 하면서 모델 사이즈를 키울 수 있습니다. 이는 효과적이고 환경 친화적으로 모델들을 키울 수 있어 더 나은 퍼포먼스 결과를 낳기도 합니다.
Multi task(여러 태스크를 한꺼번에 학습)나 continual learning(여러 태스크를 차례로 학습)기반인 dense모델들은 너무 많은 태스크 다양성은 태스크 당 하나의 모델을 훈련하는 것을 의미하는 negative interference에 취약합니다. 또한, 모델에 새로운 태스크가 추가되면 이전의 태스크들에는 안 좋은 영향을 미치는 catastrophic forgetting이 생길 수 있습니다. Sparse 모델들은 모든 인풋들이 하나의 전체 모델에 적용되지 않고, 모델 안에 있는 expert들이 다른 태스크나 데이터 타입에 전문화시키며 이러한 현상들을 해결해줍니다. 모델의 expert 사이에 공유되는 부분들은 여전히 유효합니다.
Multimodal을 처리할 수 있는 하나의 큰 모델의 필요
구글 리서치에서는 하나의 큰 모델로 수많은 태스크들과 수많은 데이터 모달리티들을 처리할 수 있게 만드는 것을 하나의 큰 연구 비전으로 삼고 있습니다. 언어(Switch, Task-MoE, GLaM)나 CV(Vision MoE)에 각각 대한 Sparse unimodal 모델들에 대해서는 상당한 진전이 이루어졌으나, 둘을 한꺼번에 처리하는 방법에 대해서는 연구가 많이 되지 않았습니다. 이와 관련된 접근법은 multimodal contrastive learning인데, 이는 사진들과 정확한 텍스트로 설명될 수 있게 하기 위해서, 이미지들과 텍스트들에 대한 견고한 이해를 필요로 합니다. 현재까지 이 태스크를 해결하기 위한 가장 강력한 모델은 각 모달리티에 독립적인 네트워크로 구성됩니다(two tower 방법).
LIMoE: the Language Image Mixture of Experts의 overview
여기서는 처음으로 큰 스케일의 멀티모달 아키텍쳐를 sparse mixture of experts를 이용하여 만들고 이름을 LIMoE라 지었습니다. 이는 동시에 이미지와 텍스트를 처리하면서 자연스럽게 전문화된 expert들을 sparse하게 발현되도록 하였습니다. LIMoE 는 많은 "expert"들을 가지고 있고, router들은 어떤 토큰이 어떤 experts로 갈 지 결정합니다. Expert 레이어들과 공유되는 shared 레이어들에서 처리된 후에, 마지막 output 레이어에서는 이미지나 텍스트를 대한 벡터 representation을 계산합니다.
Sparse Mixture-of-Experts 모델들
Transformer는 기본적으로 a sequence of vectors (토큰들)로 데이터를 표현합니다. 이는 a sequence of token으로 표현 가능하다면 사용할 수 있다는 뜻입니다. 최근에 큰 규모의 MoE 모델들은 expert layer들을 Transformer 아키텍쳐에 녹여내어 방법을 제안하였습니다. (언어쪽에서는 gShard, ST-MoE/비전쪽에서는 Vision MoE)
기존에 Transformer는 다양하고 다른 레이어들이 들어있는 많은 block들로 이루어져있었습니다. 이 중 하나가 feed-forward network라는 레이어였습니다. MoE 기반의 모델들은 이러한 FFN을 하나의 expert 레이어로 바꿨습니다. Expert 레이어는 많은 parallel FFN으로 이루어졌고 각각을 expert라고 불렀습니다. 주어진 a sequence of token를 처리하기 위해서, 하나의 심플한 라우터는 어떤 expert들이 이 토큰들을 처리해야하는 지 학습하였습니다. 오직 적은 양의 expert들이 각 토큰에 대하여 활성화되어, 많은 양의 expert가 있어 모델의 용량이 늘어난다고 해도 실제 계산 비용은 sparse하게 그들을 사용하기 때문에 어느 정도 제한이 됩니다. 만약 한 expert만 활성화된다면, 모델의 코스트는 기본 Transformer와 비슷하다는 것을 알 수 있습니다. LIMoE는 example하나당 하나의 expert를 활성화시키기 때문에 dense 베이스라인들과 계산적 비용을 비슷하게 만들지만, 라우터가 이미지나 텍스트 데이터 모두 처리할 수 있게 한다는 점이 다릅니다.
MoE 모델들이 실패할 수 있는 부분은 그들이 모든 토큰들이 같은 expert로 보낼 때입니다. 이것은 균형잡힌 expert 사용을 장려하는 추가적인 학습 objective인 auxiliary loss들로 해결될 수 있습니다. 또 다른 실패 지점은 sparsity와 상호 작용하는 다수의 모달리티들을 처리할 때 생길 수 있습니다. 이를 해결하기 위해 이 연구에서는 새로운 auxiliary loss들을 제안하고 routing prioritization(BPR)를 학습동안 사용하였습니다. 이를 통해 안정적이고 멀티모달 모델로서 높은 퍼포먼스를 낼 수 있게 되었습니다.
또한 routing 행위에서도 성공률을 높여주었는데, 낮은 성공률은 라우터가 모든 expert들을 쓰지 않고 개별 expert 용량이 차서 많은 토큰들을 드랍시키는 걸 의미합니다. 이는 sparse 모델이 잘 학습하지 못했다는 것을 뜻합니다. LIMoE에서 소개된 새로운 auxiliary loss와 BPR을 이용하면 이미지와 텍스트 모두에서 높은 라우팅 성공률을 보임을 알 수 있고 이는 훨씬 좋은 성능을 이끌어낼 수 있다고 합니다.
Contrastive 학습을 LIMoE에서 이용하기
멀티 모달 contrastive learning에서 모델들은 이미지-텍스트 페어 데이터에서 학습을 하게 됩니다. 통상적으로 이미지 모델은 이미지의 representation만 추출하게 되고, 또 다른 텍스트 모델이 텍스트의 representation을 도출하게 됩니다. Contrastive 학습은 같은 이미지-텍스트 페어에 대해서 가깝게 만들고 다른 페어들에 대해서는 최대한 멀게 만듭니다. 이를 통해 추가적인 학습 데이터 없이도 새로운 태스크들에 적용할 수 있습니다.
이러한 분류 방법을 zero-shot 분류 태스크라 하는데, 기존의 CLIP과 ALIGN이라는 two-tower 모델이 좋은 성능을 보였습니다. 여기서는 하나의 모델에서 이미지와 텍스트 representation을 모두 하기를 원하였는데, 기존의 dense모 모델들에게는 negative interference나 충분치 못한 용량 등의 이유로 성능이 떨어지는 모습을 보였습니다.
계산을 맞춰주는 LIMoE는 one-tower dense 모델뿐만 아니라 two-tower 모델들에 비해 성능이 좋아짐을 보였습니다. 여기서는 CLIP에 필적하는 훈련 기법으로 일련의 모델을 훈련했습니다. 그 결과 같은 코스트에 비해 LIMoE가 훨씬 더 좋은 성능이 나옴을 보였습니다.
아키텍쳐가 의미하는 바는 기반으로 깔려있는 Transformer의 사이즈를 의미합니다. 이는 왼쪽에서 오른쪽으로 갈수록 커집니다. S/B/L은 모델의 스케일을 뜻하는 것이고 숫자는 패치의 사이즈를 의미하는데, 작은 패치들은 더 큰 아키텍처를 의미합니다.
LiT와 BASIC은 dense two-tower 모델들의 정확도를 꽤 올려주었습니다. 스케일을 하기 위해서, 이 접근법들은 전문화된 pre-training된 방법들을 써서 이미 높은 품질의 이미지 모델을 용도 변경하였습니다. LIMoE-H/14은 이러한 pre-training이나 모달리티별 컴포넌트들 혜택을 받지 못하지만, 여전히 scratch에서부터 학습하여도 경쟁력 있는 정확도를 가짐을 확인할 수 있었습니다.
이 모델들의 스케일을 비교해보는 것도 재미있는 부분인데, 각 토큰에 쓰이는 파라미터가 적다는 것을 확인할 수 있습니다.
결론적으로, Zero-shot 이미지 분류에서는 LIMoE는 다양한 dense 멀티모달 모델들과 two-tower 방법들보다 더 나음을 보였습니다.
LIMoE가 어떻게 작동하는 지 알아보기
Sparse 기반의 조건적인 계산은 일반화된 멀티모달 모델이 여전히 각 모달을 이해하는 데 필요한 전문화를 여전히 개발할 수 있게 한다는 점이 있습니다. 여기서는 LIMoE의 expert 레이어들에 대해 분석하고 발견한 흥미로운 현상들에 대해서 설명하였습니다.
먼저, 모달리티별 expert들의 발생 현상에 대해 보았습니다. 여기에서의 훈련 설정에서는 텍스트 토큰보다 더 많은 이미지 토큰이 있어서, 모든 expert는 적어도 일부 이미지를 처리하는 경향이 있습니다. 일부 expert는 이미지 대부분을 처리하거나, 텍스트 대부분을 처리하거나 둘 다 처리하기도 합니다.
그림을 보면 1-2개의 expert은 주로 텍스트에 특화되어 있고, 2-4개의 expert는 주로 이미지에 특화되어 있고, 나머지는 그 중간 어딘가에 있습니다.
그리고 이미지 expert 사이에도 확실한 질적 패턴이 있다는 것을 확인하였습니다. 어떤 expert에서는 fauna와 greenery를 처리하고 다른데서는 사람 손을 처리하는 형식이였습니다.
결론적으로, LIMoE는 모델의 스케일을 클 수 있게 해주었고, 매우 다른 인풋들에 대해서도 학습할 수 있게 하였습니다. 이는 만물박사의 일반론자와 마스터된 전문가 사이의 긴장을 해결한다고 할 수 있습니다.
본 내용은 "LIMoE: Learning Multiple Modalities with One Sparse Mixture-of-Experts Model"을 참고하여 작성하였습니다.
일반화와 전문화를 같이 가져갈 수 있는 아이디어라는 점에서 흥미로웠다. 요즘에 mixture of expert와 contrastive learning 모두 많이 쓰이고 있는 기법인데, 이 걸 컴팩트한 문제 정의를 해서 잘 써먹었다고 생각이 든다. 어쨌든 실험들이 사진 위주로 더 잘 되어 있었서, 두 개를 개별로 봤을 때 각각 성능이 어떤 지 궁금했다. 또한, 가용할 수 있는 데이터의 수에 따른 성능의 변화도 궁금한 점이다. 데이터가 적을수록 sparse 모델이 더 성능 degradation이 일어나지 않을까한다. Sparse 모델의 좋은 점도 많지만, 이슈들이 없었는 지 좀 더 고찰이 필요한 듯했다. 끝으로, expert별로 어떤 semantic한 특징들을 뽑아낼 수 있어서 나중에 explainable ai에 쓸 수 있지 않을까하였고 앞으로 여러 관련 연구들을 진행하는 데 필요한 베이스 인사이트들 줘서 재미있는 논의 사항들이 나올 수 있을 것 같다.
반도체의 업황이 좋냐 안 좋냐는 제품의 계약 가격에 따라 달라진다. 메모리 반도체(디램(DRAM)과 낸드플래시(NAND Flash))는 7월부터 하락하고 연말까지 하락 예상합니다. 그렇다면 올해 반도체 업황은 끝난 것인가에 대해 의문점이 듭니다. 재고 축적이 8주정도 되어있어 2개월정도 소진 시간 필요합니다. 화웨이에 대한 거래 제약 때문에 특수가 벌어져서, 화웨이의 선취매(Pull and demand)는 사실 상대적으로 작년보다 강도가 적습니다. 미국의 화웨이에 대한 제재조치가 강화가 되고, 단순 모바일 AP 정도를 넘어서서 Commercial하게 가능한 칩까지도(아키텍처가 단순한 반도체까지도) 제재조치가 될 수 있습니다. IBM가 삼성 파운드리쪽에 위탁 생산을 맡긴다면 PER에 영향을 줄 수 있습니다. 이는 7나노 공정에 해당하고, 7나노가 가능한 회사의 후보군는 TSMC, 삼성 정도밖에 없습니다. 기술력 때문에 점점 플레이어들이 없어지기 때문입니다. 현재 삼성전자와 TSMC의 기술 격차는 1년정도로 기술 격차는 양산의 시기에 따라 계산합니다. 이러한 기술의 격차는 옛날에 비해 줄어들었다고 볼 수 있습니다. D램의 시장에 대해서는 걱정을 안해도 될 것으로 보입니다. SMIC은 기술격차가 커서, 14나노는 매출의 2%정도밖에 안됩니다. TSMC와 삼성은 4~5년 전에 이미 14나노 매출 비중이 커졌습니다. 14나노 매출이 커지려면 1년정도는 시간이 필요할 것으로 보입니다. 파운드리를 잘하기 위해서는 1)돈, 2)기술, 3)정부의 육성정책이 필요합니다. IBM 위탁 생산의 파급력은 삼성전자 매출 전체에는 크게 영향이 없을 수도 있지만, IBM이 위탁을 했다는 데에서 파급력이 올 것으로 보입니다. TSMC가 PER 23배정도, 삼성전자는 13배정도로, 4G땐 TSMC도 17배정도였다는 걸 감안하면 시총이 커진 걸 알 수 있습니다. 비메모리단에서 삼성전자가 영업 레버리지가 나올 국면은 케파가 2배정도 늘어나는 국면이고 500k에서 1000k되려면 10년 걸린다고 합니다. TSMC는 계속 50프로 정도 계속 유지하고 있는데, 미국에도 옛날에는 파운드리 사업이 많았다고 합니다. 다만, 시설투자 부담이 커서(리스크 테이킹) 미국의 파운드리 업체들의 위상이 약화되었습니다. 이 때는 중고 장비 트레이딩 기회도 많았다고 합니다. 왜 인텔은 비메모리 파운드리 업체에서 탈락하게 되었는 지에 대한 고찰을 하자면 2009 에서 2010년에 애플 때문이라고 볼 수 있습니다. 태블릿 PC로 인해 PC의 매출이 타격을 입어 인텔의 전방사업에 타격을 입었기 때문입니다. 인텔은 모바일 CPU에 대응을 못하였고 저전력 구현보다(QCOM, 미디어텍) 성능에 초점을 맞추었기 때문으로 보입니다. 삼성전자 8만원처럼 목표 주가를 높게 잡은 이유는, 영업이익 기준 연간 40조라 생각 때문입니다. PER도 신장(15배 정도)하고 메모리 회사가 메모리 회사보다 전통적으로 벨류에이션이 높기 때문입니다. 하이닉스의 목표주가는 10만원으로 하반기에는 변동성이 클 것으로 예상한다고 합니다.
반도체의 공정 프로세스와 관련 기업들
전공정은 2에서 3개월이 걸리고, 후공정은 훨씬 짧은 시간이 걸립니다. 후공정은 포장이라 보면 되기 때문입니다. 결국 고도화될수록 복잡해지는 것은 전공정입니다. 장비를 기준으로 90%가 전공정 관련 장비, 10% 정도가 후공정 장비입니다. 소부장 중 관심을 가질만한 것은 특히 식각공정하는 소재가 실적 개선된다는 것입니다. 관련 기업으로는 이엔에프테크놀로지가 있습니다. 에칭가스, 에칭케미칼이 식각공정할 때 세밀한 불순물 정교하게 제거하는 데 쓰입니다. 클리닝과 비교할 수 있습니다. 3D낸드처럼 적층이 많이 되면 이 같은 기술의 고도화가 필요하게 되고 관련 기업으로는 한솔케미칼이 있습니다. 후공정도 많이 까다로워졌는데 원하는 쪽에 식각하기 위해서입니다. 전기를 통하게 하기 위해 구리로 된 회로를 만듭니다. 전공정 장비를 써야해서 장비의 투자가 커서 삼성전자나 TSMC가 직접하는 경우가 많습니다. 그 외의 커버가 안되는 양의 후공정을 파트너사와 많이 하게됩니다. 대표적인 기업으로 테스나가 있습니다. 후공정에는 패키징과 테스팅이 있음. 패키징은 가내수공업, 테스팅은 서비스에 가깝습니다. 시장의 파이가 커지면 수혜를 입게 됩니다. 장비사들은 소부장 국산화 덕분에 영업해서 매출하는 기간이 짧아지게 되었습니다. 비메모리쪽이 많이 장비를 사가게 되고 1~2분기에 장비를 더 사가는 게 은연중에 반영됩니다. 따라서 비메모리쪽에 특화되어 있는 코스닥 업체들이 많습니다.코미코는 후공정하여 세정서비스를 하고 있습니다. 세밀하게 닦아낼 수 있는 섬세한 작업이 필요하기 위해 엄청난 노하우가 필요합니다.
2차 전지는 LG 화학, SK 이노베이션, 삼성SDI 등에서 현재 만들고 있습니다. 이는 3가지 가루로 이루어져 있는데, 실리콘 음극재, CNT 도전재, 전해질들&전해 첨가제입니다. 전기차의 선두주자인 테슬라의 주행거리는 이전 완성차 업체에 비해 이미 벌어져 있습니다.
양극은 리튬 이온을 만들고 주행거리 결정합니다. 양극재를 하이니켈로 하는 이유는 빵빵하게 이온을 만들기 위해서입니다. 음극은 만든 리튬을 저장하는 곳으로 스펀지처럼 빨아들이면 충전시간이 줄어듭니다. 왔다 갔다 할 때 매개체가 되는 전해질 특성을 개선시키는 것도 중요합니다. 현재는 양극의 하이니켈 만드는 업체들이 포커싱되어 있습니다. 예를 들어 에코프로비엠, 엘앤에프가 있습니다. 업사이드 포텐션쪽에서는 음극재나 전해질 쪽이 큽니다. 대주전자재료, 동진쎄미켐, 한솔케미칼 등의 업체가 있습니다.
양극을 만드는 업체들이 하이니켈로 가는 방향은 같습니다. LG화학 기준 6(니켈)2(코발트)2(망간)에서 712로 변경하는 것이 목표입니다. 양극은 늘리는 방안 이미 시행중에 있습니다. 음극을 만드는 업체에서는 에너지 케파를 늘리기 위해 실리콘 첨가제 추가해야 합니다. 충전시간이 적어지는 효과가 있게 되고 2022년부터 본격화될 듯합니다. 전해질을 연구하는 업체에서는 추가적인 신규 전해질 첨가(+D,+B)로 수명을 연장하는 방법 강구하고 있습니다. 이 모든 것은 기술적인 부분은 연구되었던 것으로 논문에 있는 기술을 상용화 중에 있는 것으로 보시면 됩니다.
전기차 시장의 성장과 그에 따른 전망
2025년까지 1200만대로 전기차 판매가 될 것으로 추정됩니다. EV도 엄청나게 늘어나게 될 것입니다. 이에 따라 음극 SI첨가제는 현재 133억에서 2025년에는 5조의 시장이 될 것으로 추정합니다. CNT는 현재 70.6억에서 2025년 2조의 시장이 될 것으로 추정합니다. 이는 침투율이 0~1%밖에 안되기 때문입니다. 2025년에는 침투율(채택하는 자동차 모델의 비율) 실리콘 첨가제가 60%, CNT 양극재가 55%, 음극재가 50% 될 것으로 추정합니다. 판매단가가 급격하게 줄어들지 않는다고 가정한 이유는 농도가 계속 높아질 것이기 때문입니다. 퀄리티가 높아지니 단가에는 크게 영향을 받지 않을 것으로 보입니다.
테슬라는 자체적으로 배터리를 만들겠다 선언을 했습니다. 9월달 테슬라 배터리데이에서 공식적으로 언급할 것으로 예상합니다. 완성차 업체들은 주행거리, 충전 시간, 수명 향상, 저온 특성을 배터리 업체들에게 요구할 수밖에 없을 것입니다.
2차전지 시장에서 남아있는 과제들
실리콘 음극재는 저장 그릇이 많이 필요합니다(실리콘). 흑연은 리튬 이온 1개 저장시 탄소분자 6개 필요(-6)하게 됩니다. 실리콘은 분자 하나가 리튬이온 4.4개 저장(4.4). 실리콘의 저장 용량이 10배정도 향상시키기 때문에 충전시간 감소에도 도움이 됩니다. 이 때까지는 실리콘의 물리적 팽창이 4.4배 늘어나서 문제였습니다. 이는, 1. 물리적으로 구조적 불안정 : 자꾸 팽창수축하면 소재에 문제가 생기고, 2. 리튬 트랩 : SI층에서 전자를 막아줘서 전류를 만들어내는데 실리콘의 팽창수축 때문에 이 구조가 깨지기 때문에 배터리 수명 단축되었습니다. 이를 해결하기 위한 방법으로는 1. 나노 사이즈로 줄이거나, 2-1. 실리콘 산화막 형식으로 물리적으로 팽창하는 것을 막아주거나(대주전자재료) 2-2. 실리콘 탄소복합체를 이용하여 실리콘을 처음부터 탄소계 물질로 코팅하여 코팅된 힘이 물리적 팽창을 막아주는(삼성 SDI와 삼성 종기원에서 기술이전 후 양상 준비를 하는 한솔케미칼) 방식이 있습니다. 양극재의 퍼포먼스가 좋아지면 그를 담는 그릇인 음극재도 좋아져야 합니다.
CNT(탄소나노튜브) 도전재는 활물질 내에서 전자들의 이동 통로 역할로, 원재료를 만드는 것은 쉬우나 CNT의 강한 응집력을 분산시키는 것이 핵심입니다. 따라서 진입장벽이 있습니다. 고속충전(고전압)시에도 배터리 수명이 줄어들지 않는데 역할을 해줍니다. 양극재형 CNT은 전도도가 높고, 기존에 쓰던 것의 20%만 써도 같은 성능이 나옵니다. 어차피 2~4%밖에 차지를 안해서 줄여봤자 큰 의미가 없습니다. 차라리 하이니켈이 좀 더 파워풀하다고 할 수 있습니다. 양극의 용매는 NNP라고 용해도가 높습니다. LG화학, 나노신소재 등에서 담당하고 있습니다. 음극재형 CNT는 실리콘의 팽창 문제를 보완 해결 가능합니다. 음극의 용매는 물로서 용해도가 떨어집니다. 나노신소재에서 이러한 소재를 만들고 있습니다.
하이니켈 사용시 주행거리는 어차피 늘어날 것은 보장됩니다. 충전 시간에 대해 더 불만이 생길 것이고 주행 거리 이외의 개선을 위해서는 첨가제 사용이 필수가 될 것입니다.
현재 2차 전지의 기술의 진입장벽 자체가 높고, 현재 배터리 3사가 국내 업체와 손잡고 하다 보니 국내 업체들의 기술력이 좋아질 수밖에 없는 상황으로 좋은 양상을 띄고 있다고 할 수 있습니다.