PEGASUS 설명
오늘은 추상적인 텍스트 요약 모델(PEGASUS: A State-of-the-Art Model for Abstractive Text Summarization)에 대한 내용입니다. ICML 2020 논문이랍니다. 텍스트 요약 생성을 위해 RNN, Transformer encoder-decoder 등이 많이 쓰입니다. 특히, 요즘에는 semi-supervised를 동반하는 transformer 모델들이 잘 쓰임입니다. 대표적인 예시가 BERT입니다. 만약 self-supervised 목표 자체가 최종 태스크를 더 잘 반영한다면 더 성능이 좋은 모델이 될 것으로 예상됩니다.
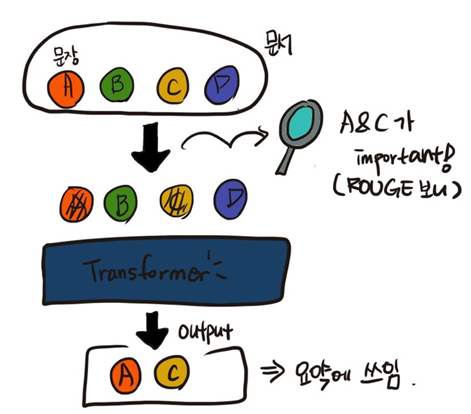
pre-training 시에 문서에서 어떤 문장들을 지우고, transformer의 결과를 지워진 문장들이 합쳐서 나오는 형식으로 학습합니다. 이는 실제로 현실에서 있을 수 있는 실제적인 (혹은 노이지 한) 현상들을 반영할 수도 있고, 최종 태스크인 fine-tuning 요약의 아웃풋과 유사하게 만들기 위해 문서에서 필요한 정보를 추출하는 방법으로 쓰일 수도 있습니다. 이때 문서에서 "중요한" 문장을 잘 지우는 게(mask) 중요한데, 이때 n-gram을 기반으로 하는 ROUGE 유사성 척도를 이용합니다. 디테일하게는 T5 모델을 이용하여 웹 크롤링 된 문서들로 pre-training을 하고 12개의 specific 한 태스크 기반의 데이터 셋들을 이용하여 텍스트 요약을 진행하게 됩니다. 결론적으로는 좋은 성능을 얻을 수 있게 되었습니다.
실험 결과
state-of-art 만큼의 성능을 내기 위해서 fine-tuning 용 데이터가 생각보다 많이 필요 없습니다. 1000개 이상이면 어느 정도 supervised에 수렴하고, sample이 많지 않아도 돼서 annotation 부담이 줄어드게 됩니다. ROUGE는 기계적인 평가이기 때문에 실제 유창성 등을 평가하기 위해 사람 기반의 평가도 동반하였고, 적은 데이터(1000개)로 만들어진 요약도 충분히 사람들에게 받아들여짐이 나타났습니다. 실제 요약 사례에서, 정확히 배의 종류 개수에 대해 스스로 세어서 요약됨을 알 수 있습니다. 하지만 이 종류가 어느 정도 이상이 되면 잘못 세어지는 현상이 생깁니다. 어쨌든 모델 스스로 알아낸다는 점에서는 흥미롭습니다.
연구에 대한 의견
Pre-traning 시에 이미 final 태스크에 대해 어느 정도 포커싱을 하고 학습 모델을 만들면 결국 fine-tuning에서 더 좋은 결과가 나올 수 있습니다. 점점 Dataset이 적어도 충분히 그 도메인에 적용될 수 있는 방안들이 고안되고 있는 것 같습니다. 이에 따라 ML을 사용할 수 있는 도메인도 점점 늘어날 듯합니다. 이제 데이터가 없어서 할 수 없어요라는 말은 점점 사라지고 다른 데이터 간을 어떠한 연관관계를 가지는지 알아내는 게 더 중요해지는 것 같습니다.
어제 공부한 것과 연관시켜 생각해 볼 때, 다른 나라의 문서라도 바로 내가 원하는 나라의 문서로 요약되는 효율적인 모델을 만들 수 있지 않을까 합니다. 물론 요약 모델에서 번역 모델 이렇게 하면 당연히 지금도 되겠지만 2단계로 진행해야 하니, 그냥 바로 번역된 문장으로 요약되는 하나의 모델로 할 수 있는 방안은 고안해야 할 것으로 보입니다. 이러면 블롬버그 같은 데서 나오는 기사를 바로 이해할 수 있을 지도 모르겠습니다. 확실히 BERT 이후, NLP 쪽은 이런 방향으로 많이 연구가 되고 있다는 생각이 들고, NLP도 결과가 시각적으로 볼 수 있어서 재미있는 부분이 많아진 것 같습니다.
'NLP' 카테고리의 다른 글
| T5 , 텍스트-텍스트 전이 트래스포머 (0) | 2022.06.05 |
|---|