기존 모델의 다국적 언어를 지원하기 위한 한계
오늘 공부할 것은 언어에 구애받지 않는 BERT 기반 문장 임베딩(Language-Agnostic BERT Sentence Embedding)에 대한 내용입니다. 다국어 임베딩 모델은 같은 임베딩 공간에 다른 언어들을 인코딩시키기에 강력한 도구입니다. 이는 텍스트 분류, 클러스터링 또는 언어 이해 등 다양한 태스크에 쓰일 수 있습니다.
이전 방법론들은(LASER나 m~USE) 서로 다른 언어들 간의 문장 임베딩 일관성을 향상시키기 위해 한 문장에서 다른 언어의 한 문장으로 매핑시키는 방법을 씁니다. 이들은 밀접하게 연관된 표현들을 얻기 위해 번역 쌍을 학습 데이터로 쓰는 번역 순위 태스크(translation ranking tasks)같은 곳에 적용될 때 종종 연관된 이중 언어 모델(en-xx)에 비해 고자원의 언어(en)에서 성능이 안 좋아집니다. 모델 케파의 한계와 저자원 언어의 질나쁜 학습 데이터 때문에, 좋은 성능으로 수많은 언어들을 지원하도록 다국어 모델을 확장시키기가 어렵습니다.
MLM pre-training의 제안과 여전한 한계
언어 모델을 개선하기 위해서 MLM pre-training 기법들(BERT, ALBERT, RoBERTa)이 제안되었습니다. 이는 단일 언어 텍스트만 필요하기 때문에 다양한 언어들과 다양한 언어 처리 태스크에서 좋은 성능을 냈습니다. 또한, MLM pre-taining은 MLM 학습에 연결된 번역 쌍을 포함하거나(translation language modeling (TLM)) 단순하게 여러 언어들의 사전 학습 데이터를 도입하여 다국어 환경으로 확장할 수 있었습니다. 이런 MLM이나 TLM 학습으로 학습된 표현법들은 (문장 단위에 목표가 아닌)태스크에 맞게 fine-tuning하는데 도움이 되었지만 번역 태스크에 중요한 문장 임베딩을 바로 만들 수는 없다는 한계점이 있었습니다.
이전 연구에서, 번역 순위 태스크를 이용해 다국어 문장 임베딩 공간을 학습하여, 주어진 소스 언어 문장에서 타겟 언어들의 문장 모음에 대해 (잘 된 것에 따라)순위를 매기는 방식입니다. 이는 공유하는 트랜스포머 인코더를 가지는 듀얼 인코더 구조가 되는데 이는 다중 병렬 텍스트 검색 태스크에서 좋은 성능을 내게 되었습니다. 그러나, 이 모델은 모델의 용량, 어휘의 범위, 학습 데이터 퀄리티 등으로 인해 이중 언어 모델이 여러언어를 지원하도록 확장할 때 문제가 생겼습니다.
다국어 BERT 임베딩 모델
본 연구에서는 LaBSE라는 다국어 BERT 임베딩 모델을 만들었습니다. 이는 109개의 언어들에 대해 언어에 구애받지 않는 교차 언어 문장 임베딩 생성을 만드는 데 도움이됩니다.
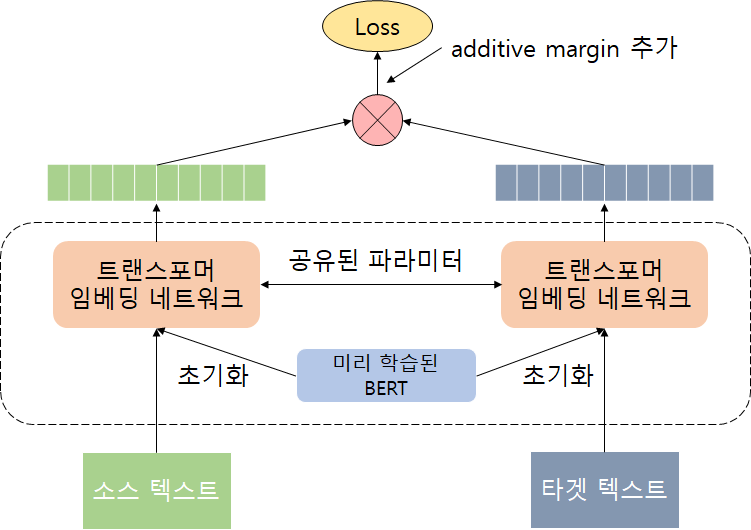
기본적으로 듀얼 인코더 구조로 소스와 타겟 문서는 공유된 임베딩 네트워크에 각각 인코딩됩니다. 번역 순위 태스크가 적용되면 서로를 의역하는 텍스트들은 비슷한 표현법들을 가지도록 만듭니다. 트랜스포머 임베딩 네트워크는 MLM이나 TSM 태스크에 의해 학습된 BERT 체크포인트에 의해 초기화됩니다. 모델은 MLM및 TLM 사전 학습을 사용하여 170억개의 단일 언어 문장과 60억개의 이중 문장 쌍으로 학습을 하였고, 학습 때 데이터가 없었던 저자원의 언어에서도 효과적인 성능을 보였습니다.
텍스트 검색 테스크 실험 및 결과 분석
다국어 텍스트 검색 태스크에 대해서 Tatoeba corpus를 이용해 실험하였습니다. 30개의 언어가 학습데이터에 해당 언어가 존재하지 않았습니다. 모델은 주어진 문장에 대해 consine distance를 계산하여 비슷한 문장을 알아냅니다. 기존 benchmark들이 커버했던 것에 따라 그룹을 4가지(14개, 36개, 86개, 전체(112개))로 나누었습니다. 많이 커버하는 14개의 언어들에 대해서는 m~USE 와 LASER, LaBSE 모두 좋은 결과를 냈습니다. 커버하는 언어가 많아질수록 정확도는 낮아졌지만 LaBSE가 더 완만하게 낮아졌습니다. m~USE는 14개 이상 커버가 안 되는 것을 확인할 수 있었습니다. 30개 이상의 학습 데이터에 없는 언어들에도 적용 가능하다는 것을 확인하였습니다.
| Model | 14 | 36 | 82 | All |
| m~USE (transformer ver) | 93.9 | - | - | - |
| LASER | 95.3 | 84.4 | 75.9 | 65.5 |
| LaBSE | 95.3 | 95.0 | 87.3 | 83.7 |
본 연구는 웹 스케일의 병렬적 텍스트에 대해 마이닝 하는 데도 쓰일 수 있다고 합니다. 본 연구에서는 병렬적 텍스트 추출을 위해 대규모 코퍼스인 CommonCrawl에 LaBSE를 적용하여 엄청난 양의 중국어와 독일어 문장을 처리합니다. 각 중국어와 독일어 문장 쌍은 LaBSE모델을 기반으로 인코딩되고 인코딩된 임베딩은 인코딩된 77억개의 영어 문장들 중에서 잠재적인 번역 후보를 찼아 대략적으로 가까운 문장을 찾는 알고리즘을 통해 고차원의 문장 임베딩에서 비교적 빨리 찾을 수 있습니다. 이를 통해 많은 수의 영어-중국어, 영어-독일어 잠재 번역 후보들을 찾을 수 있었습니다. 이는 고품질의 병렬 데이터로 훈련된 현재의 최고 모델과 크게 차이나지 않았습니다.