손가락 힘 기반의 제스처 센싱
오늘은 픽셀 4에서 손가락 힘 기반의 제스처 센싱(Sensing Force-Based Gestures on the Pixel 4)에 대한 내용이다. 터치 입력은 두드리거나 스와이프 하는 등의 모션 외에 길게 누르는 방법이 있습니다. 길게 누르는 방법은 사용자가 꽤 오랜 시간(시간 임곗값만큼) 동안 누르고 있어야 합니다. 이런 방법은 시스템과 사용자 간의 즉각적인 상호작용을 하는 데 한계가 생깁니다. 디바이스에서 누르는 위치뿐만 아니라 손가락의 누르는 힘도 입력을 받을 수 있기 때문입니다. 손가락 힘을 센싱 하기 위해서 하드웨어 센서에 종속되는 경우가 많습니다. 하드웨어가 충족되더라도, 손가락 입력 시 사용자가 힘을 미세하게 조절하기 힘들므로 몇 개의 레벨로만 나누어서 입력을 받아들이는 경우가 많아서 하드웨어 센서를 유용하게 사용 못 하게 되는 결과를 낳습니다.
Pixel4에서의 제스처 분류 학습
Pixel4에서는 더 많은 터치 상호작용을 할 수 있도록 손가락 힘 기반의 제스처 센싱 기법을 고안하였습니다. 사용자가 터치 센서들과의 상호작용을 어떻게 하는지 분석한 후 길게 누르는 상호작용을 좀 더 자연스럽게 할 수 있도록 지원해 주었습니다.

일단 터치 센서는 두 가지의 전도성 전극으로 구성됩니다. 구동(drive) 전극과 센싱 전극(sense)라고 불립니다. 두 전극은 유리와 같은 비전도성 유전체를 중간에 두고 떨어져 있다는 특징이 있습니다. 두 전극은 셀(tiny capacitor)을 만들어 어느 정도의 전하를 갖고 있습니다. 만약 손과 같은 전도성 물체가 다가간다면 전하를 뺏기게 되고, 정전 용량이 줄어듦을 알 수 있습니다. 따라서, 뺏긴 전하의 양은 손가락과 전극들 사이의 거리에 반비례하게 됩니다.

셀들은 디바이스의 화면에 매트릭스로서 표현될 수 있습니다. (물론 디스플레이의 픽셀보다는 한 칸의 크기가 큽니다.) 이 표시되는 매트릭스들을 레코딩합니다. 손가락을 닿는 부분을 최대한 중심으로 만들고 손가락 주변부에 대해서는 다르게 반응하기 위해, 터치 센서는 손가락 힘이 변하는 것에 초점을 두지 않고, 디스플레이와의 거리에 대해서 좀 더 민감하게 반응하게 합니다.
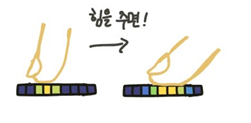
만약 사용자가 화면을 누른다면 화면에 닿이는 손가락의 면적이 넓어지는데, 면적이 넓어지면서 달라지는 두 가지 속성을 알 수 있습니다. 초기 접촉점을 중심으로 비대칭적으로 닿이는 부분이 변화한다는 것과 닿이는 중심점이 손가락의 축을 따라 이동한다는 것입니다. 이를 통해 초기 매트릭스와 손가락 힘을 준 후 변화하는 매트릭스를 통해 접촉 모양의 변화를 감지 가능합니다.
사용자의 손가락 모양이나 화면의 각도에 따라 닿이는 면적이 달라질 수 있습니다. 사용자마다 접촉 모양 변화는 다를 수 있으므로 ML을 이용하여 압력 제스처 분류 학습합니다.
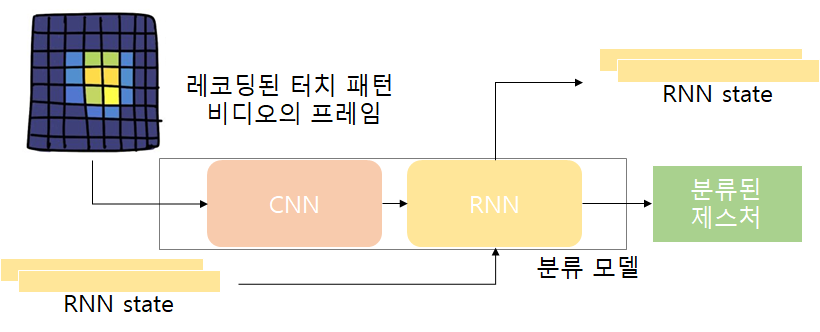
사용자에게 터치 후 즉각적인 정보 제공을 위해서 분류는 실시간성을 띄어야 하고 손가락 힘이 정점일 때 빠르게 상호작용을 해줘야 합니다. CNN을 이용하여 공간적인 특성을 뽑아내고 RNN을 이용하여 시간적인 특성을 뽑아내고 RNN이 프레임별로 처리되어 실시간성 경험에 기여합니다. 온디바이스 추론을 위해 추론 구조 단순화하였다고 합니다. 압력 제스처와 4가지의 터치 제스처를 학습하고 제대로 구별되기 위해 loss function도 구성하였습니다.
제스처의 UX와의 비교 및 논의해야할 점
기존의 오랜 시간 터치와 제안한 압력 제스처의 UX 비교해 보았을 때 압력 제스처가 사용자가 터치 시에 출력되는 결과와 연결이 더 잘 되는 결과를 낳았습니다. API를 제공하므로 아무나 도입 가능하다고 합니다.
뭔가 용두사미가 된 느낌이 있는데, 새로운 터치 기법을 추가된 것이 새로운 점인 것 같습니다. 지금 실험이 픽셀 4에서 하나의 예시만 들어서 다른 환경(디바이스)에서 다른 예시가 좀 더 필요하다고 생각합니다. 매트릭스를 잘 만들고 ML 기법도 도입하였는데 압력 제스처 하나만 알아내는 것에만 쓰이는 게 조금 아깝다는 생각이 들어서 혹시 다른 터치 관련된 문제에 도입할 수는 없을지 생각해 봐야 할 것 같습니다. 마지막으로, 하드웨어랑 소프트웨어가 결합된 문제여서 신기했습니다. 다만, 성능에 대한 결과 비교가 더 필요하고 상용화가 실제로 되었을 때 어떤 문제점이 있는지에 대한 논의도 좀 더 되어야 할 것으로 보입니다.

